Develop, Preview, Test
@rauchg|June 11, 2020 (3y ago)20,626 views
A few years ago I tweeted a simple guideline that challenged conventional wisdom and became the norm for many people learning how to test their frontends effectively.
Writing tests is an investment, and like any other investment, it has to be evaluated in terms of its return and risks (e.g.: opportunity costs) it incurs in.
The "not too many" keys in on that. There is, after all, too much of a good thing when it comes to spending time writing tests instead of features. We can see an application of this insight also to availability by Google's popular SRE book:
You might expect Google to try to build 100% reliable services—ones that never fail. It turns out that past a certain point, however, increasing reliability is worse for a service (and its users) rather than better! Extreme reliability comes at a cost: maximizing stability limits how fast new features can be developed and how quickly products can be delivered to users, and dramatically increases their cost, which in turn reduces the numbers of features a team can afford to offer
In this essay I want to make the case that prioritizing end-to-end (E2E) testing for the critical parts of your app will reduce risk and give you the best return. Further, I'll show how you can adopt this methodology in mere minutes.
#Why end-to-end?
In addition to integration tests, I want to now make the case that modern deployment workflows in combination with serverless testing solutions can now fully revert the conventional testing pyramid:
![[object Object]](/_next/image?url=%2Fimages%2Fdevelop-preview-test%2Fpyramid.jpg&w=2048&q=75) Martin Fowler's conventional testing pyramid. What if 🐢 and 💲 went away?
Martin Fowler's conventional testing pyramid. What if 🐢 and 💲 went away?
As it turns out, focusing on the customer first is the best way to run a business, but also the best way to ascertain software quality.
You might be using the fanciest new compiler, the newest type system, but
won't do well if, after you ship, your site doesn't load in Chrome at all
because you forgot to send the right HTTP headers for your .js files.
Or you use features not compatible with Safari.
Modern cloud software has a great deal of complexity that cannot be ascertained "in the lab", or by running artificial tests in your computer. We normally deploy software to dozens of operating systems, mobile devices, web browsers, networks of varying stability and performance… And the environment is always changing, as we take more and more dependencies on hosted services and third-party APIs.
Furthermore, software quality goes beyond correctness. It's not just about doing "the right thing". Quality encapsulates reliability (whether your program stays working correctly over time) and performance (it must do the right thing quickly).
#End-to-end made possible
First, back when I argued for focusing on integration in 2016 and made no mention of end-to-end tests, we didn't yet have the deployment infrastructure we have today.
With Vercel, every push to git gets deployed and given an URL. This can be done cost effectively by focusing on incremental computation, where the underlying static files and serverless functions used to power a deployment are mostly re-used from deploy to deploy.
![[object Object]](/_next/image?url=%2Fimages%2Fdevelop-preview-test%2Fgithub-comment.jpg&w=3840&q=75) An example of a PR automatically deployed for this very blog
An example of a PR automatically deployed for this very blog
Just like GitHub is capable of keeping the history of your code forever, so can Vercel. Because deploys are stateless, the resources are only used on-demand and scale infinitely with traffic.
That gets rid of an obvious initial objection: that it would be difficult or costly to perform end-to-end tests against a live individualized version of your website. Instead of thinking about a single staging server that end-to-end tests are run against, now you can have millions of concurrent "staging" environments.
I say "staging" in quotes because in reality, you run tests against the real production infrastructure, which has enormous reliability benefits. Not only are certain features these days only enabled when SSL is on, but having every other production feature enabled, like brotli compression and HTTP/2, reduces your risk of outages:
The way I think about it: ever difference between dev/staging/prod will eventually result in an outage.
Having made staging instant, prod-like and cost-effective, the remaining objection is that running the actual end-to-end tests would be expensive or slow, going by the pyramid above.
However, the introduction of puppeteer, Chrome's headless web browser, combined with serverless compute that can instantly scale to thousands of concurrent executions (see this Stanford paper for an example) are now making E2E both fast and cheap.
#End-to-end made easy
To show the Develop -> Preview -> Test workflow in action, I'm going to demonstrate how easily I can add an E2E test for my open-source blog using Vercel in combination with Checkly on top of GitHub.
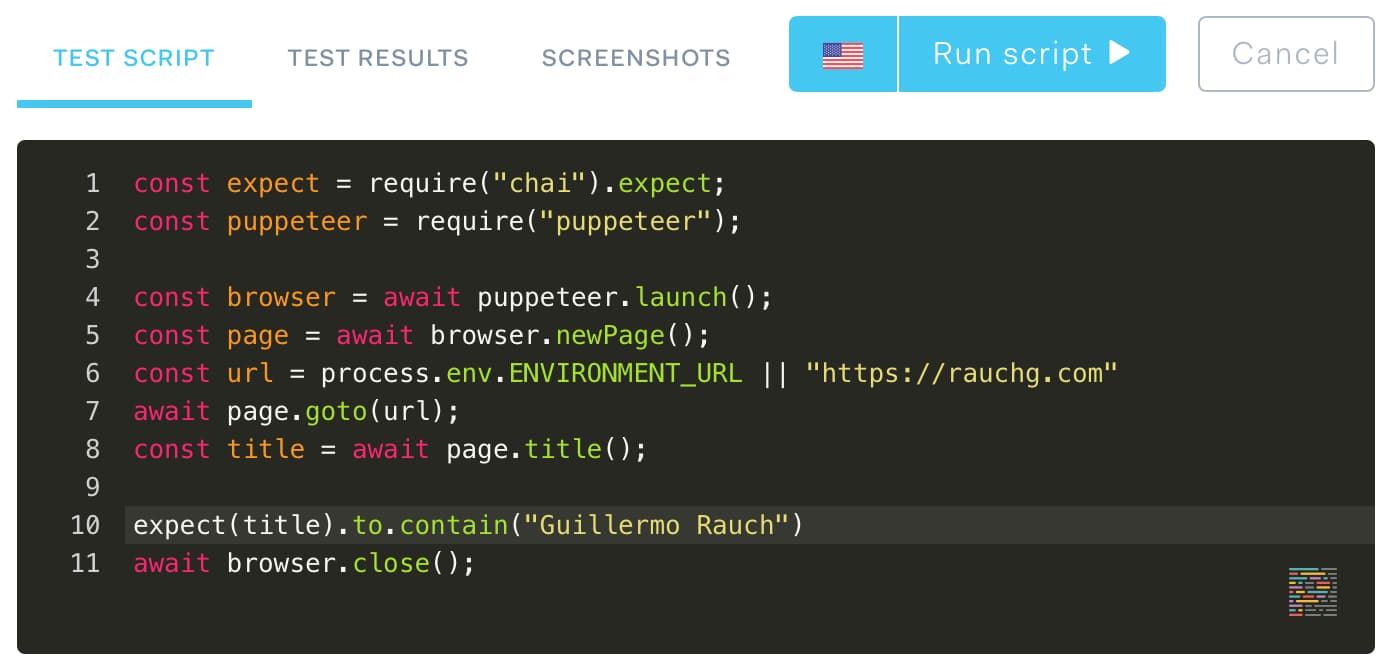
First, I'm going to define an end-to-end test to ascertain that my blog always contains the string "Guillermo Rauch" in the browser title. As I'm writing this, it's not the case, so I expect this to fail.
Checkly gives me full access to the Node and puppeteer APIs. Notice I don't have to write any ceremony, setup or scheduling logic. I'm "inside" the function that will later be invoked:
Then, I installed the
Checkly GitHub app
and under the CI/CD tab of the check, I linked it to my
rauchg/blog repository.
I created a git branch where I introduced the <title>
tag for my blog, but on purpose
I misspelt my name.
As soon as I created my pull request, the check was already failing. In just a few seconds, I pushed, deployed, a headless browser simulating a visitor ran, and my error was exposed:

This happened with absolutely zero additional configuration. Vercel supplied a URL, Checkly tested it, GitHub was notified. After pushing again, the check re-runs automatically:

With my typo fixed, I'm free to merge. Merging to master will deploy my
changes to rauchg.com automatically.

#Conclusion
Notably, Checkly allows us to configure multiple locations in the world that the tests get executed from, as well as
invoking our checks over time.
Leslie Lamport famously said that a distributed system is one where "the failure of a computer you didn't even know existed can render your own computer unusable".
As our systems become more complex, with ever-changing platforms and dependencies on other cloud systems, continuously testing just like our users do is our best bet to tame the chaos.